DeepSeek-R1, an efficient model reasoner
Here are my notes on the paper DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Introduction
OpenAI was the first one that introduces a series of models with reasoning capabilities (OpenAI, 2024b). Introduces the inference-time scaling by increasing the length of the Chain-ofThought reasoning process. This approach has significantly improved LLM results.
To achieve the goal of obtaining a reasoning model DeepSeek uses Reinforcement Learning (RL) and DeepSeek-V3-Base as a base model. For improve the reasoning of the model they incorporate a small amount of cold-start data to fine-tune the DeepSeek-V3-Base model and multi-stage training pipeline. DeepSeek create a new Supervised Fine-Tuning (SFT) data through rejection sampling and combined with supervised data from DeepSeek-V3 in domains such as writing, factual QA, and self-cognition.
DeepSeek introduces Distillation Models these models are small but with good performance. Using a reasoning pattern with data generated from DeepSeek-R1 DeepSeek refines several dense models like Qwen or Llama. With this technique the models perform very well in benchmarks.
Approach
DeepSeek use Reinforcement Learning (RL) in DeepSeek-R1-Zero without any supervised data.
Reinforcement Learning Algorithm
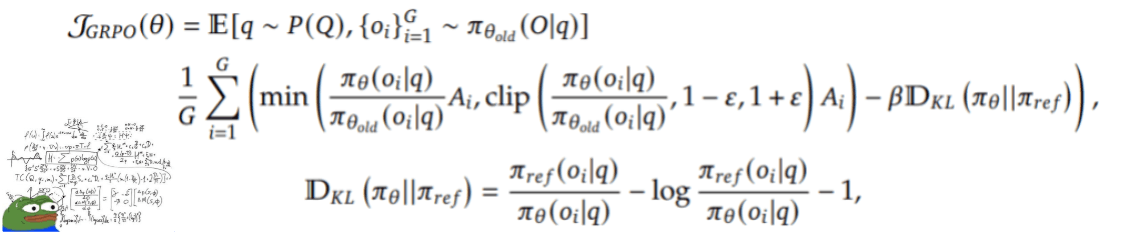 When we do RL with a language model, we have a preference dataset so we have some questions and then we ask the language model to generate multiple answers and then we ask the annotators to choose the answer they like and with that we train a reward model that will give signals to the language model to know if the answers it is generating are good or bad.
When we do RL with a language model, we have a preference dataset so we have some questions and then we ask the language model to generate multiple answers and then we ask the annotators to choose the answer they like and with that we train a reward model that will give signals to the language model to know if the answers it is generating are good or bad.
This algorithm will then find a Policy where the model will give more weight to those actions that result in a good reward and give less weight to those that are less likely to be a good reward.
💬 Policy: The Policy is the brain of the Agent, it’s the function that tells what action to take given the state. So it defines the agent’s behavior at a given time. Reinforcement learning methods specify how the agent’s policy is changed as a result of its experience.
Reward Modeling
DeepSeek use a rule-based reward system with 2 types of rewards:
- Accuracy rewards: Evaluates whether the response is correct. For this in necessary provide the final answer for a enabling reliable rule-based verification of correctness. As a mathematical problem and its answer.
- Format rewards: reward the model for putting the thought of its response in
<think>and</think>tags
Training Template
This template makes the model always do the reasoning process followed by the final answer.
Performance, Self-evolution Process and Aha Moment of DeepSeek-R1-Zero
These graphs show us the increase of performance of the model. We can see how de DeepSeek-R1-Zero starts AIME 2024 from an initial 15.6% and pass to e 71.0%. And get results close to OpenAI-o1-0912.
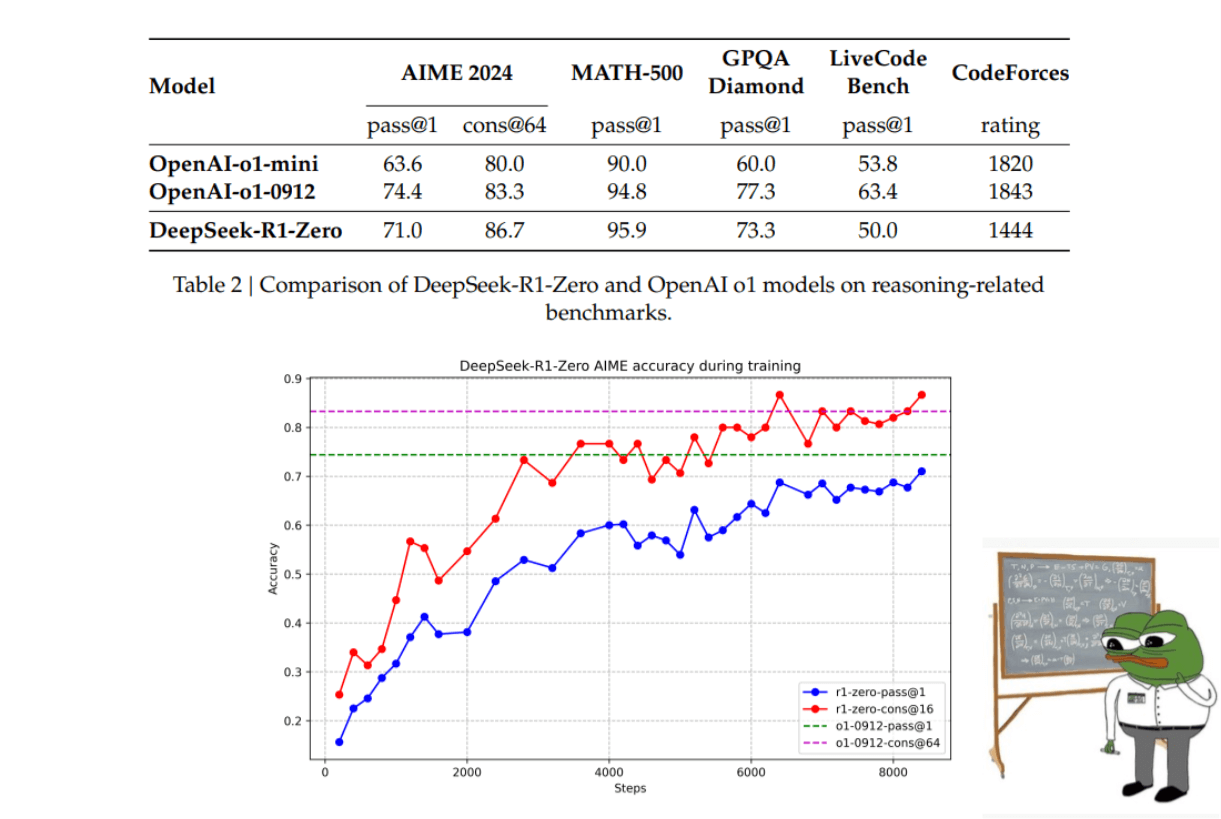
DeepSeek-R1-Zero achieves great reasoning capability without using supervised fine-tuning data. This is impressive because it shows us the model's ability to learn and generalize with RL alone.
Self-evolution Process of DeepSeek-R1-Zero The model has the ability to evolve its reasoning capabilities autonomously. Without a supervised fine-tuning stage the model demonstrates that it evolves over time and its ability to handle complex reasoning tasks.
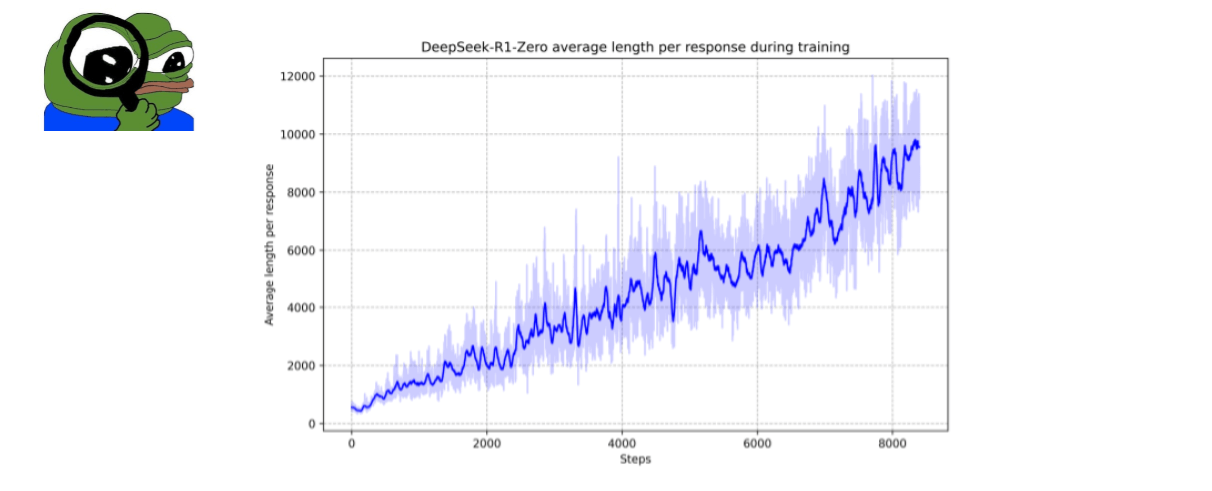 The paper notes that as the computation in test time increases the model develops behaviors such as reflection which makes the model look at its previous steps and re-evaluate them.
The paper notes that as the computation in test time increases the model develops behaviors such as reflection which makes the model look at its previous steps and re-evaluate them.
DeepSeek-R1: Reinforcement Learning with Cold Start
DeepSeek-R1-Zero has some problems such as when faced with poor readability and language mixing.
For improve DeepSeek-R1-Zero and create DeepSeek-R1 DeepSeek create a pipeline of four stages.
1. Cold Start
To avoid the cold start stage problem, DeepSeek built and collected long CoT data to fine-tune the model as the initial RL actor.
📌 The cold start phase refers to the initial stage where the agent/model has no prior experience or data to make informed decisions, having to learn from scratch.
DeepSeek-R1-Zero struggles with readability, often mixing languages and lacking proper formatting. In contrast, DeepSeek-R1 improves this by structuring responses with a reasoning process and a summary, ensuring clarity. By designing better cold-start data with human priors, DeepSeek-R1 achieves superior performance, highlighting the benefits of iterative training for reasoning models.
2. Reasoning-oriented Reinforcement Learning
After fitting DeepSeek-V3-Base to the cold start data, they applied the same reinforcement learning process they used with DeepSeek-R1-Zero.
They found that CoTs often mixed languages, and to address this they introduced a reward for linguistic consistency during RL training.
3. Rejection Sampling and Supervised Fine-Tuning
The model was trained in two phases: first, using Reinforcement Learning focused on reasoning to obtain a checkpoint; and then, using Supervised Fine Tuning (SFT), a diverse dataset was collected including 600k reasoning samples-generated and carefully filtered using techniques such as rejection sampling and evaluated with a DeepSeek-V3 generative reward model and 200k general task samples (such as writing, translation, and QA). Finally, the base model was refined over two epochs, extending its capabilities beyond pure reasoning.
Rejection sampling is a statistical technique used to generate samples from a complicated distribution from a simpler distribution from which it is easy to draw samples. The basic idea is to propose a candidate from the simpler distribution and, using an acceptance rule (based on the relationship between the density function of the target distribution and the proposed one), decide whether to accept or reject that candidate. If rejected, another candidate is generated and the process is repeated until a valid sample is obtained. This method is useful when direct sampling from the target distribution is difficult.
4. Reinforcement Learning for all Scenarios
A second learning phase was implemented to align the model with human preferences, improving both its usability and safety, while refining its reasoning ability. To this end, the use of reward signals and a diversity of prompts is combined: rule-based rewards (according to the DeepSeek-R1-Zero methodology) are applied for mathematics, programming and logic tasks, and reward models are used to capture human preferences in general scenarios. In addition, the focus is on utility being reflected in the final response summary, while evaluation of the full response helps mitigate risks and biases. This integration allows training a model that excels both in its reasoning ability and in being useful and safe.
Distillation: Empower Small Models with Reasoning Capability
Smaller models, such as Qwen and Llama, were trained by direct SFT using 800k DeepSeek-R1 samples, with the aim of providing them with reasoning capabilities. Different variants (Qwen2.5 and Llama) were employed and, unlike the original approach, the reinforcement learning stage was omitted to demonstrate the effectiveness of this distillation method.
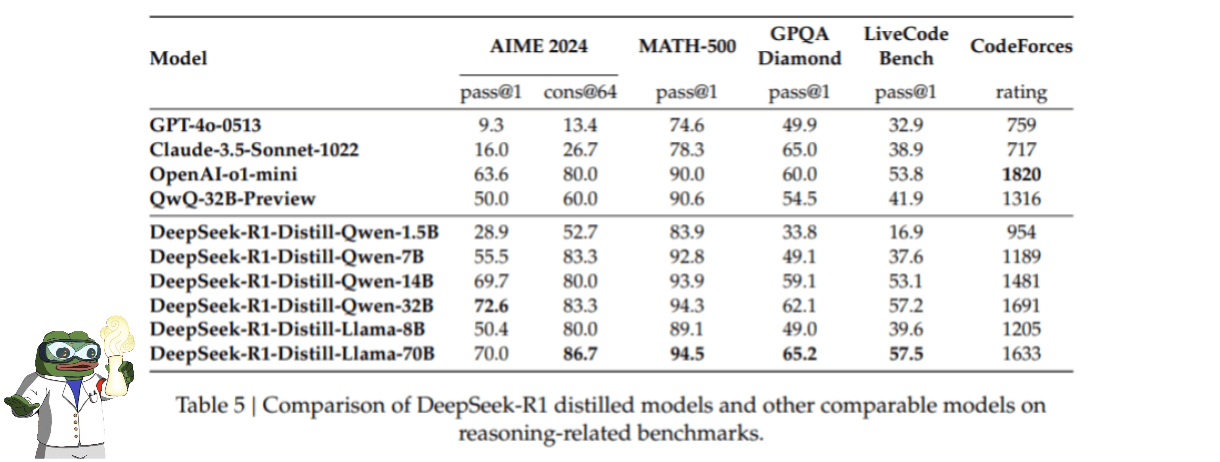
Distillation of DeepSeek-R1 outputs allows models such as DeepSeek-R1-7B to outperform models without reasoning capabilities (e.g., GPT-4o-0513) on all metrics evaluated. In addition, DeepSeek-R1-14B outperforms QwQ-32BPreview, and models DeepSeek-R1-32B and DeepSeek-R1-70B score significantly better than o1-mini on most benchmarks. These findings highlight the great potential of distillation, and although applying RL to these distilled models has been found to yield notable improvements, only results obtained using supervised fine tuning (SFT) are presented here.
The future is bright, final thoughts
The future looks bright. We are managing to have very competent models running on our local devices, which is really amazing. Can you imagine that?
Imagine having three or more artificial intelligence models running on your devices, helping you to create new solutions, to be better professionals, to do more advanced research and to increase your productivity.
To me, this is extremely exciting. Ever since I was a kid watching the Iron Man movie, I was fascinated by how Tony Stark built his armor with the help of Jarvis. While we will probably never build a suit of armor like Iron Man's, these low-cost, locally operated models will allow us to develop tools and applications that bring significant value to our communities and the world.
With a solid knowledge base, we will be able to experience exponential growth. Teachers who used to take a week to prepare courses for their students will now be able to do so in a day, adding more value to their classes; programmers will develop applications more quickly; and accountants will analyze their businesses' financials in less time, making decision-making easier.
Although there are still challenges to solve-such as optimizing the use of resources and making it accessible to all-this is just the beginning. We need to keep building and moving forward to take full advantage of these transformative technologies.
Resources
- Trading Inference-Time Compute for Adversarial Robustness
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- What is Rejection Sampling?
- An introduction to rejection sampling
- Paper: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- DeepSeek R1 Explained to your grandma
- Understanding the concept of cold start ai
- Reinforcement Learning - Hugging Face